
Solving PHP Scaling Issues
We have an export feature that can build an Excel file over the course of many background jobs. Worked beautifully for years. Man, those were the days.
We have an export feature in one of our PHP projects. Given a data source, it will build an Excel file over the course of many background jobs. Once the file is complete, a final job will be kicked off to email the user a tokenized link for download. This strategy has worked beautifully, without any significant issue in years. That is, until, as you might have guessed by the title, it didn't.
Nothing Special Here
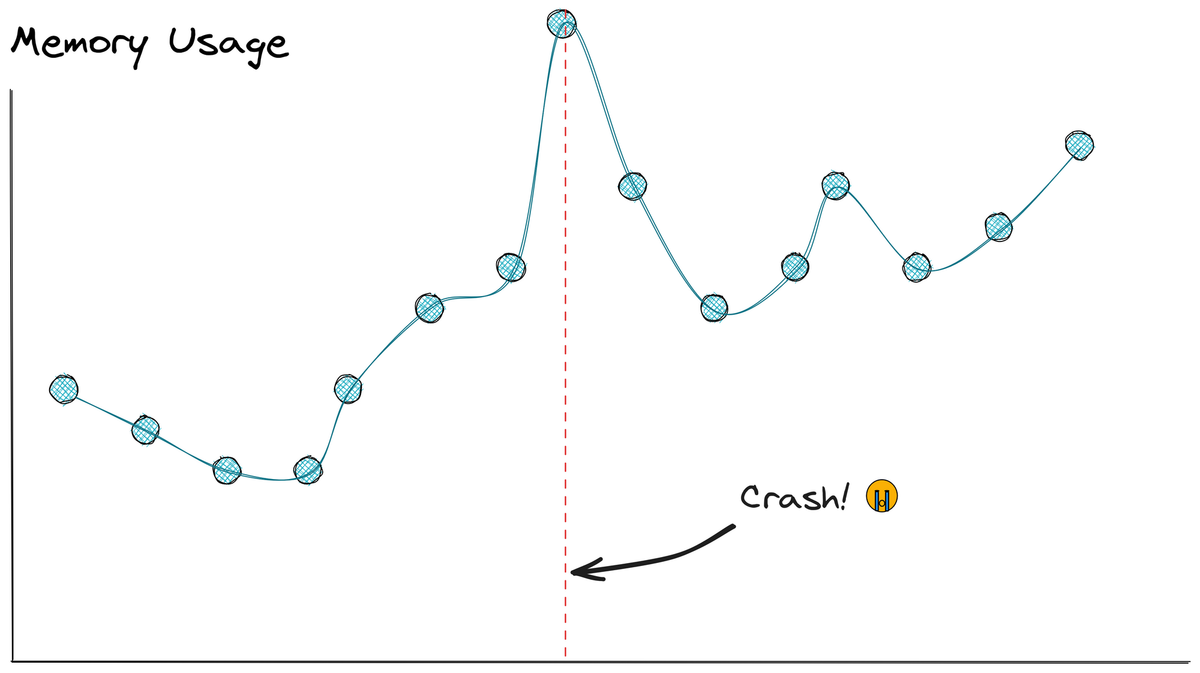
Before we get into the nitty gritty, allow me to set the stage. This export feature was designed, built, and refined over years just like anything else. We've made regular updates, and we've had to fix the occasional bug or two. But none so deeply rooted or head-scratching as the memory issues we began to see with only our largest customers.
This didn't begin happening just after some update to it, either. The otherwise reliable system that had served us for years suddenly hit a roadblock. A point at which beyond it was no longer able to function properly.
Surprised as we were, support tickets began to pile up, it became clear that we needed to dig deep into the issue and find a solution as soon as possible.
Bigger Seeder
Our first step in troubleshooting was to reproduce the issue in a controlled environment. We had no failing tests, and we couldn't reproduce the issue using seeded data locally. Not a great beginning. Our seeder was only large enough to be able to test things out and make the application feel somewhat realistic.
Using our largest customer as a reference, we created another seeder that would generate a dataset that was roughly the same size as their database in production. Bingo! This allowed us to consistently reproduce the issue.
Memory Leak?
I just knew there had to be a memory leak somewhere. Call it a Peter Tingle. This assumption seemed safe, given the symptoms we were observing. Laravel's queue worker runs continuously, so we were likely not cleaning things up properly.
We spent the next few weeks making incredible progress; scratching our heads, profiling memory usage, raising eyebrows, exploring alternate strategies, and accomplishing absolutely nothing. In what must be truly record time, a brow-raising realization hit us; maybe this was not a memory leak. Maybe this wasn't a bug. Maybe everything was working just as it's supposed to.
I guess you could call this part of the journey a "failure", but I choose to use the term "learning experience".
The Anatomy of Exporting
To understand the problem, we first need to dissect the mechanics of this process. The ten thousand foot view looks something like this:
- User Initiates Export: The user clicks a link or sets up a schedule for regular exports in their inbox.
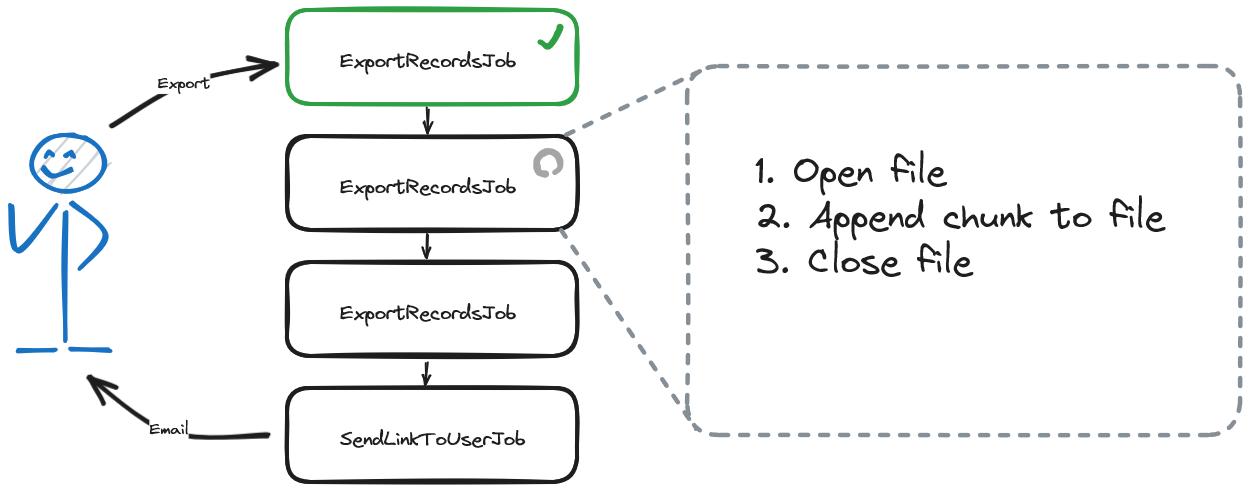
- Export Job Chain: A background job chain is kicked off where each job is responsible for opening an Excel file, appending a chunk of records to the file, and then closing the file.
- Tokenized Link Creation: Once the export is complete, another job is triggered to send an email with a tokenized link. This link allowed them to securely download their export.
Unveiling the Culprit
As we peeled back the layers of the exporting system, it became clear that this was no bug; everything was working exactly the way it was designed to.
Bus::chain([
new ExportRecords(1, 500),
new ExportRecords(501, 1000),
new ExportRecords(1001, 1500),
// ...,
])->dispatch();Each job opened the Excel file, appended a chunk of records, and then closed the file. Any one of these jobs could fail, affording us the time to fix it, and subsequently retry the failed job. The job chain would pick back up where it left off and finish the export. We could kill the queue worker half way through, and when we turned it back on it would resume as if nothing happened. Someone could trip over the power cord at the data center, and the user would never know there was a problem. While this design was highly resilient, it wasn't designed for the higher volume we were now seeing.
This seemingly innocuous process of opening the file at the beginning of each job was causing a significant problem. It would require loading the entire file's contents into memory. This means each job consumes more and more memory, especially in the latter half. Once the file is opened, appending to it will increase it even more. This is why we didn't encounter this issue with lower volume. It hadn't reached the memory limit.
Long-running process
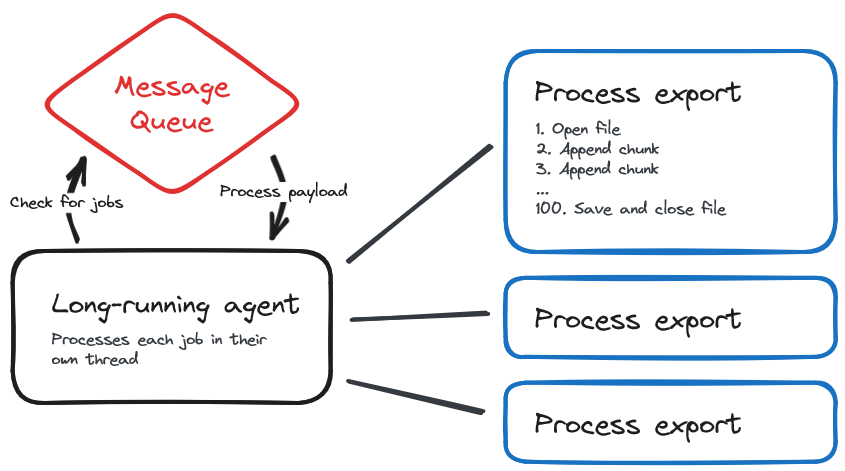
With the problem identified, we needed to find a solution that could efficiently manage memory and handle the demands of large data exports. In other words, instead of opening/closing the file for each chunk of records, we needed a long-running process where the file was opened once at the beginning and closed at the end. Doing so would mean that the entire contents of the file was never completely kept in memory at one time. An empty file would be "opened" at the start, and we would evict the memory after each chunk, keeping memory usage low.
This would mean sacrificing the ability to resume building the export where it left off. We would now need to restart the export entirely if something happened that would stop the export mid way.
But there was a problem. We weren't comfortable with extending job timeouts to the amount we would need in order to accommodate our largest exports. It felt like prolonging the inevitable.
Increase PHP's memory limit?
We considered this, but not for very long. PHP already uses quite a bit of memory. Typically, we use this memory limit as a smell. An early warning system that we may not be doing something right. Increasing the memory limit would buy us some time, sure, but we would soon be in the same position with no solution, and no early warning system.
No. We needed a real fix, not a band-aid. We needed something... different. Perhaps entirely different, we began to wonder.
Rust!
Rust is blazingly fast and memory-efficient: with no runtime or garbage collector, it can power performance-critical services, run on embedded devices, and easily integrate with other languages.
The answer to our problem came in the form of Rust, a systems programming language known for the characteristics that our export process sorely needed.
Rust’s rich type system and ownership model guarantee memory-safety and thread-safety — enabling you to eliminate many classes of bugs at compile-time.
Eliminating common pit falls at compile-time would empower us with confidence even though it was new to us. These beautiful compile-time checks, however, would come at a cost.
The Learning Curve
No one in our team was already familiar with Rust, so there was a considerable learning curve involved in adopting the language. We not only had to figure out how to rewrite our export system to solve the problems we were seeing, but also had to learn new syntax, new tools, and a new ecosystem of packages (crates). Luckily we had each other to learn from and help push past errors as they came up.
We've never been afraid of adopting or embracing promising new technologies. If it gives us an advantage, we don't mind dealing with the inherent difficulties and instability of the bleeding edge.
After moving beyond our initial points of friction, we actually found Rust's syntax and concepts to be rewarding, once we became accustomed to them. In fact, we started missing some of Rust's features in our other languages! (Rust's enums are 🔥)
Communication
Now that we were handing this process off to a completely separate service, the question became, how do we communicate between the two? The rust service needs to know when an export has been requested. The PHP side needs to know when the file is ready. What we ended up doing was fairly straight forward.
Upon a user triggering an export, we create a Export record in the database, assigning it a unique ID. Then a JSON payload is added to a redis queue. Our new Rust agent monitors this queue and will process jobs as they become available.
Once the file is successfully built, we initiate an HTTP webhook with JSON back to the customer's instance (each customer has a unique url) so that the email and link can be sent to the original user.
We considered using gRPC here. Rust and PHP are both supported. At the end of the day, we needed to rely on something we already knew and understood well so that we could get this out the door. Maybe later.
Conclusion
For us, Rust was the better choice for our long-running tasks due to its memory safety, concurrency support, and performance. As with anything in engineering, there are trade-offs with every decision. The decision to use Rust was based on the specific requirements and constraints of our project. Rust's ability to efficiently handle long-running tasks and enforce correctness made it the ideal choice for our team.